Case Study: Creating Grains and Hierarchies
To illustrate the concept of grains and how Birst transforms data into an analytical application, we will use the Northwind Traders example dataset. Its simple physical data model is illustrated below.
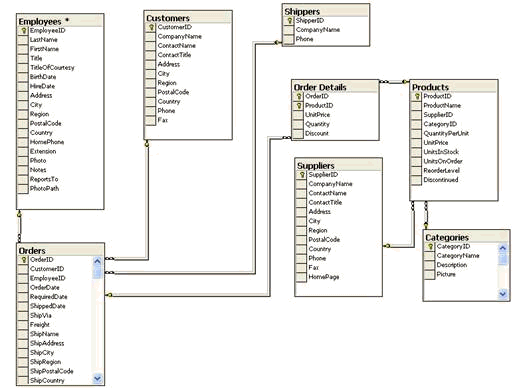
This structure is organized the way the information is created from a simple order management system. There are orders, and for each order there are one or more line items for each product on that order. Products are grouped into categories and orders are made by customers and employees.
Defining Hierarchies and Levels
The first step in building a model for this data set is to decide on the hierarchies to be utilized for analysis. Hierarchies allow for convenient navigation from higher levels of summarization to more detailed views. Since the core of this data set revolves around orders, it makes sense to have a hierarchy around orders. At the lowest level are order line items. Those line items roll up into individual orders and those orders can roll up into customers.
Using the Hierarchies page under the Define Sources tab in Admin, we would create a hierarchy for Orders and add a level for each level where we would like to analyze data. For each level, we also select the columns that create a key for that level. A key uniquely defines each element in that level. At a given level there should be no duplications of a level key – this way the system can always look up the right information at that level using the key. In the case of Northwind, the level key for the Orders level is the OrderID column. There is one OrderID for each order.
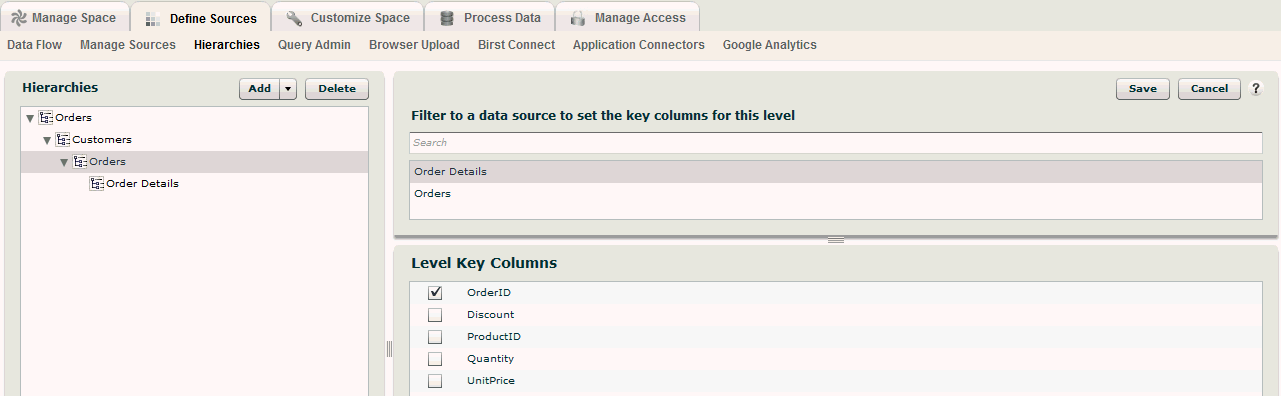
For the Order Details data, the level key is the combination of OrderID and ProductID – there can be only one record for each product for each order.
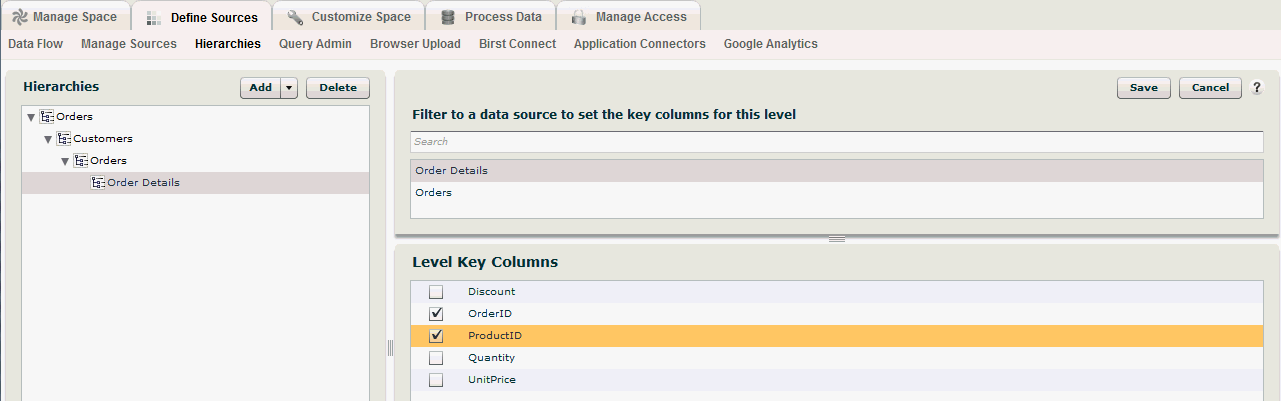
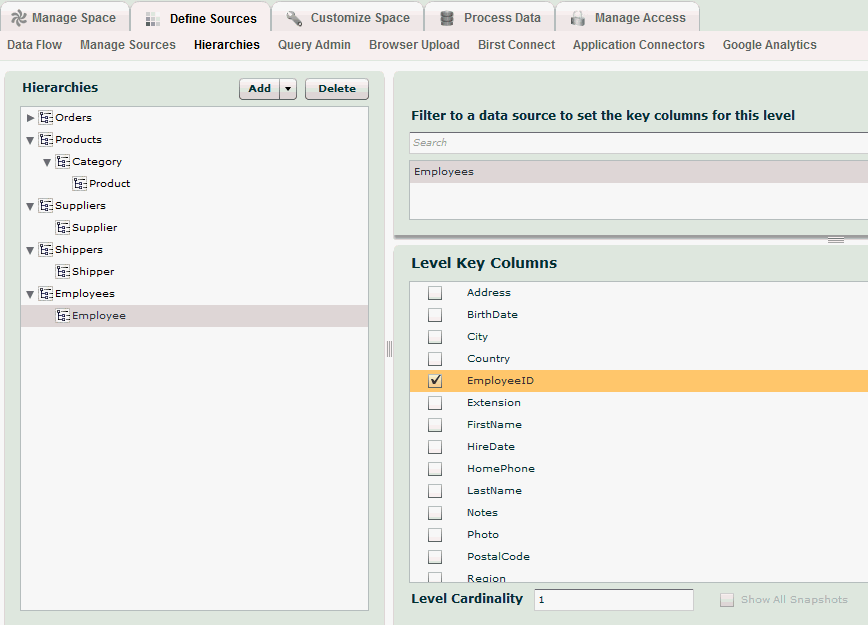
You could also define hierarchies for Products, Suppliers, Shippers and Employees as illustrated below. The Employee level of the Employees hierarchy is uniquely identified by the EmployeeID column.
Defining the Grain of the Data Sources
When all the hierarchies are set up, we can then relate these hierarchies to the incoming data sources. Once Birst understands how hierarchies relate to incoming data, it can build a sophisticated analytical data structure suitable for decision-making analysis. That is, in essence, what a grain is. A grain defines what hierarchy levels apply to each data source. For example, the Employees data source is data at the Employees level. In the Grain tab of the Manage Sources page, we would select the Employee level of the Employees hierarchy to identify its grain. That tells Birst that each record in this data source is unique to one employee. Similarly, the Orders data source contains data at the Orders level of the Orders hierarchy and data at the Employee level of the Employees hierarchy as shown below.
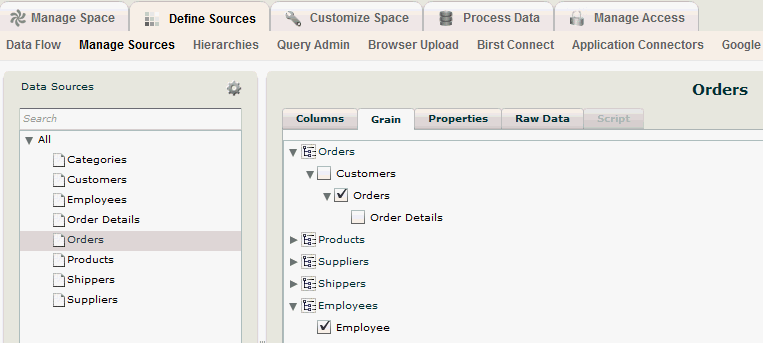
In the Orders table, the grain is the combination of the levels Orders and Employee (and time, although time is always implicit). It is critical that the grain of each source represent a unique combination of records throughout time for data that spans multiple time frames. In this case the Order ID is unique through time, however for some systems that re-use IDs, the Order ID would need to be combined with the Order Date to truly uniquely identify an order throughout historical time.
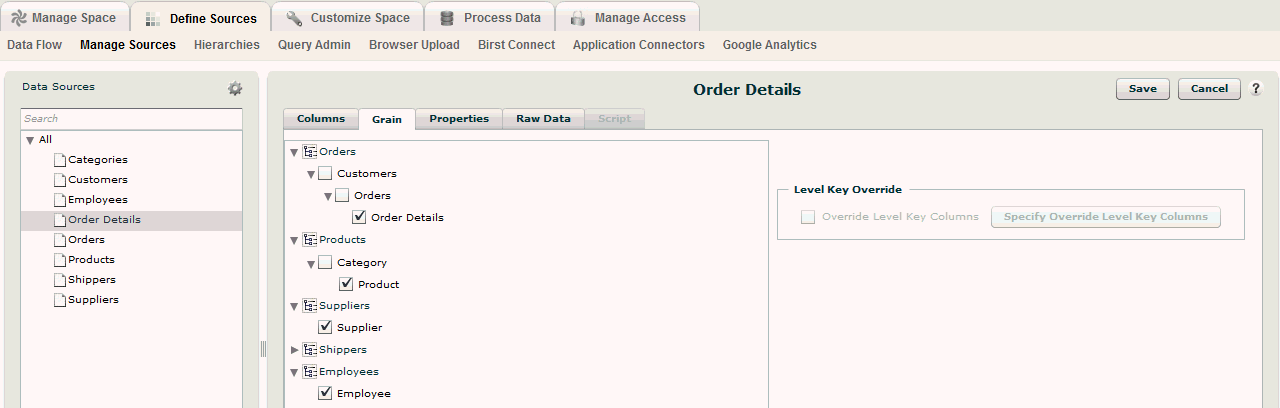
In a more complex example, the Order Details source is clearly at a lower level than the Orders source. For each Order there are one or more Order Detail line items. There may be one or more product line items for each order so the level key for the Orders detail level is a combination of OrderID and ProductID. In addition, Order Details is at the Product level so that can be added to the grain of that source.
See Also
Creating a Data Model
Creating Hierarchies
Defining the Grain of a Data Source
Defining Column Properties
Overriding Level Keys