Update Warehouse Model
For an Advanced space type using a Birst data store (warehouse), you can create a data model by labeling each column as a measure, attribute or both, deciding which hierarchies to create and mapping them onto the various sources, and labeling which levels are part of the grain of each source.
Alternatively, for Advanced spaces using a warehouse you can use Update Warehouse Model from the Admin - Define Sources - Data Flow tab. This option derives a dimensional data model for your source data based solely on the initial key/foreign key relationships setup. Using this approach, you do not need to manually create and manage hierarchies and grains.
Best Practice: Use Update Warehouse Model as a first step. For subsequent updates, processing the space will update the model. You do not have to click this option again.
Consider the following data model:
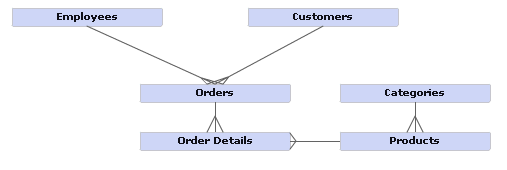
When data sources are uploaded, Birst automatically assigns the primary key columns for each data source. You can view or modify the default assignments by right-clicking a data source in Data Flow and selecting Set Primary Key. After creating joins between your sources, you can click the Update button on the Data Flow tab to update the warehouse model. Birst will leverage information in the data source data model and automatically create the dimensional data model shown below.
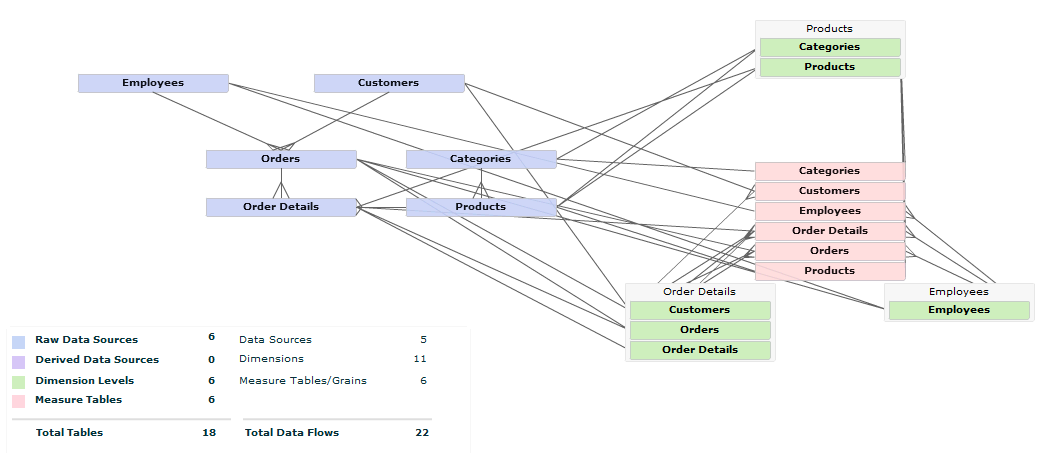
Update Warehouse Model uses the following procedure to determine which hierarchies to build and how to target them.
-
Create a hierarchy for each data source:
- The hierarchy name is the same as the source.
- There is one level in the hierarchy also with the same name.
- The level key of this level is the same as the primary key of the data source.
-
Each potential attribute column (Varchars and Integers) is targeted to the associated hierarchy of its source.
-
Each potential metric (numeric values) is designated as a measure.
-
Each date is selected to “Analyze by Date”.
-
Every source is set to a grain that includes only the level with its own name.
-
Hierarchies with dependent levels are folded together into multi-level hierarchies:
-
A dependent level is one that has a one to many relationship with another level. For example, the Customers level is initially in its own Customers hierarchy. But since there is a one-to- many relationship (as indicated by the data model) between Customers and Orders, Customers can be merged into the Orders dimension as a level higher than Orders.
-
This folding continues until it is not possible to combine any more hierarchies.
-
Utilize key/foreign key relationships to set implied grains. In the example of Orders above, after folding, the Orders table would have only one level in its grain: Orders. (Customers would simply be a higher level in the same dimension.) But Employees also has a one-to-many relationship to Orders. For levels such as Employees that have this one-to-many relationship but cannot be folded into a hierarchy because another was already chosen, they are added to the grain of the source. Hence, after this process, Orders has two levels in its grain: Orders and Employees.
This process of creating levels, folding hierarchies together, and identifying implied grains using key/foreign key information creates a complete dimensional data model and maps it onto the source data. This algorithm (except in very advanced cases) eliminates the need for designers to create and manage hierarchies and grains manually. As new sources are added, Birst will update this data model. However, if data has been processed, Birst will lock the existing hierarchies and grains in place and only create new ones for the new sources—preserving any initial structures that were created. This allows you to create a model and add to it over time.
See Also
Creating a Data Model
Defining Column Properties
About Joins
Setting up Joins
Setting the Primary Key