Product Line Structural Definition
A product line is a complete set of programs. The information that defines the product line is defined by using the Lawson Database Definition utility (dbdef). There is one database definition for each product line, data area, and data ID. The database definition is stored in the GEN database. The GEN database contains information about all of the product lines, data areas, and data IDs defined in that environment. On a high level, the product line definition has two components, structure and data.
The structural definition includes:
-
System codes
-
Attachment space
-
Elements and fields
-
Derived fields including string and group fields
-
Conditions, compute, and array value fields
-
Text for elements and fields
-
Values and translations
-
Database relations, conditions, and subtypes
-
Database rules, states, and events
Most of the above are described in the Lawson Application Development Workbench Standards manual.
The data definition includes location and file sizes.
The file sizes are defined and stored in the data area and data ID portion of the product line. Data IDs are sub-areas of data areas with a set of data all their own. Together with the structural component, the data areas and data IDs make up the product line. An entire product line or individual data areas and data IDs may be secured from user access.
Database Spaces
A database space is the storage area for your database files. You are required to set up database spaces so the Lawson system knows where to store your data.
You can assign database spaces to each data area, system code, and file. When you assign a space to a file, the data for that file is stored in the location defined by that database space. If a file does not have a database space, the data is stored in the system code's database space. If the system code does not have a database space, the data area's database space is used.
Indexes, Index Keys, and Conditions
Indexes are sets of fields that the Lawson system uses to access and order records in a file. Every file must have at least one index. Fields that make up an index are called index key fields.
Using an index in a query makes the search much faster because the query looks only at records defined by the index. When a user makes a request through a Lawson form that involves searching the database to return a list of records, the system constructs a database call. Specifying an index and at least one value for an index key tells the system to search only records that match those values, which makes the query more efficient. The system returns records in the order defined by the index.
Conditions are statements that can be applied to files, indexes, or relations to limit the number of records returned in a search. An index that has a condition applied to it contains only records that meet the criteria defined in the condition.
Relations
Relations connect one or more records from one file to one or more records in another file so data can be shared between the files when needed. The system searches for and return records from more than one file if the files are related.
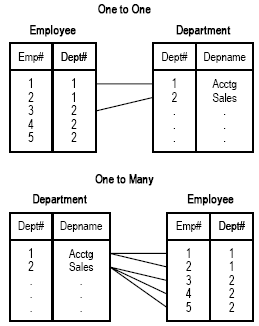
There are two main types of relations:
-
A one-to-one relation connects one record from a primary file to one record from a secondary file. For example, a one-to-one relation could exist from the EMPLOYEE file to the DEPARTMENT file, indicating that one employee belongs to one department. The DEPARTMENT field, which supplies the department number and occurs in both files, relates and connects the files.
-
A one-to-many relation connects one record from the primary file to many records in the secondary file. For example, a one-to-many relation could exist from the DEPARTMENT file to the EMPLOYEE file, indicating that the data for a particular department also has related data for multiple employees.