Fuzzy Matching
Fuzzy matching is a technique for identifying similarities between strings that do not exactly match each other. Fuzzy matching lets you apply a threshold matching percentage, above which you can say that two strings "approximately match".
Fuzzy Matching in ETL
Fuzzy matching is useful for ETL data cleansing operations. For example, you may need to detect that personal names were entered into the system with different spellings but that they all refer to the same person.
There are many important algorithms that support fuzzy matching for various types of data matching. ETL provides a useful set of them with the STRINGDIST and PHONETIC functions.
STRINGDIST
STRINGDIST provides distance algorithms for strings to determine the differences, referred to as the "distance", between two strings.
STRINGDIST('Levenshtein|JaroWinkler|Qgram|Ngram|Jaccard|Cosine',[Dimension.Column1], [Dimension.Column2]
Options include:
- Levenshtein: The Levenshtein metric string distance between two words is the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one word into the other. In Wikipedia see Levenshtein distance.
- Jaro-Winkler: The Jaro-Winkler string edit distance helpd detect duplicates in records. It is best suited for short strings such as personal names, and to detect typos. In Wikipedia see Jaro–Winkler distance.
- NGram: An n-gram distance was defined by Kondrak in "N-Gram Similarity and Distance", String Processing and Information Retrieval, Lecture Notes in Computer Science Volume 3772, 2005, pp 115-126. In Wikipedia see n-gram.
- QGram: The Q-gram distance was defined by Ukkonen in "Approximate string-matching with q-grams and maximal matches" .
- Cosine: The cosine distance defines a similarity in subject matter between two documents based on the number of times that the same terms appear in each. In Wikipedia see Cosine similarity.
- Jaccard: The Jaccard distance compares the dissimilarity between data sets, and is the complement of the Jaccard index. In Wikipedia see Jaccard index.
PHONETIC
The PHONETIC function uses phonetic algorithms to provide a method of indexing strings by their pronunciation. These are useful for matching English-language words. Phonetic transformation algorithms to create a code that represents how a string sounds as it is pronounced. For example, if two strings have the same Metaphone code, they are likely to sound alike.
PHONETIC('Soundex|Metaphone|DoubleMetaphone',[Dimension.Column1], [Dimension.Column2]
Options include:
- Soundex: The Soundex option encodes a string into a Soundex value. Soundex is an encoding used to relate similar names, but can also be used as a general purpose scheme to find word with similar phonemes. See the Wikipedia entry Soundex.
- Metaphone: The Metaphone option encodes a string into a Metaphone value and is appropriate for basic English words. See the Wikipedia entry Metaphone.
- DoubleMetaphone: The DoubleMetaphone option supports more complex English words that are based on other languages. See the Wikipedia entry Metaphone.
Example Results of ETL Fuzzy Matching Functions
The following example shows how to upload data that you want to match, and apply the fuzzy matching functions to a scripted source.
- Start with data similar to the following. It should have two columns of strings that almost match each other.
| Col1 | Col2 |
| abcdd | abbcd |
| ab | bxa |
| abcde | abdcde |
| Cosmo Kramer | Cosmo Kramer |
| Kosmo Kramer | Cosmo Kramer |
| Comso Kramer | Cosmo Kramer |
| Csmo Kramer | Cosmo Kramer |
| Cosmo X. Kramer | Cosmo Kramer |
| Kramer, Cosmo | Cosmo Kramer |
| Jerry Seinfeld | Cosmo Kramer |
| CKaemmoorrs | Cosmo Kramer |
| Cosmer Kramo | Cosmo Kramer |
| Kosmoo Karme | Cosmo Kramer |
| George Costanza | Cosmo Kramer |
| Elaine Benes | Cosmo Kramer |
| Dr. Van Nostren | Cosmo Kramer |
| remarK omsoC | Cosmo Kramer |
| Mr. Kramer | Cosmo Kramer |
| Sir Cosmo Kramer | Cosmo Kramer |
| C.o.s.m.o. .K.r.a.m.e.r | Cosmo Kramer |
| CsoKae | Cosmo Kramer |
| Coso Kraer | Cosmo Kramer |
- Upload it to an Advanced space and enable the source.
- In Admin - Define Sources - Manage Sources - Data Sources click the gear icon and select Add Script.
- Name the script and save it.
- Add the columns and click Save.
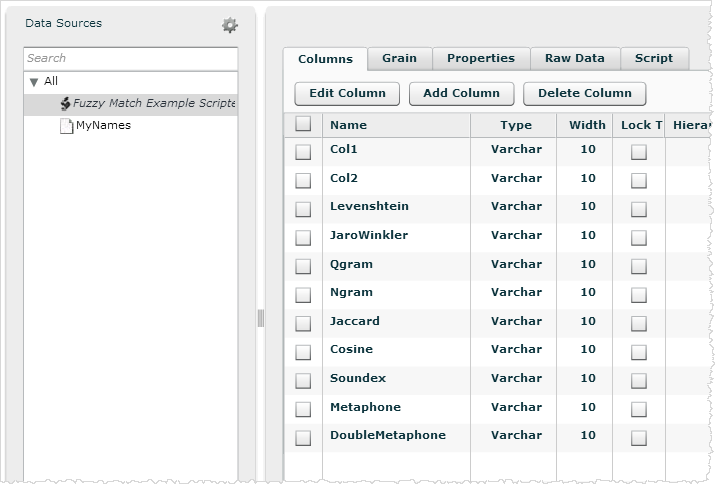
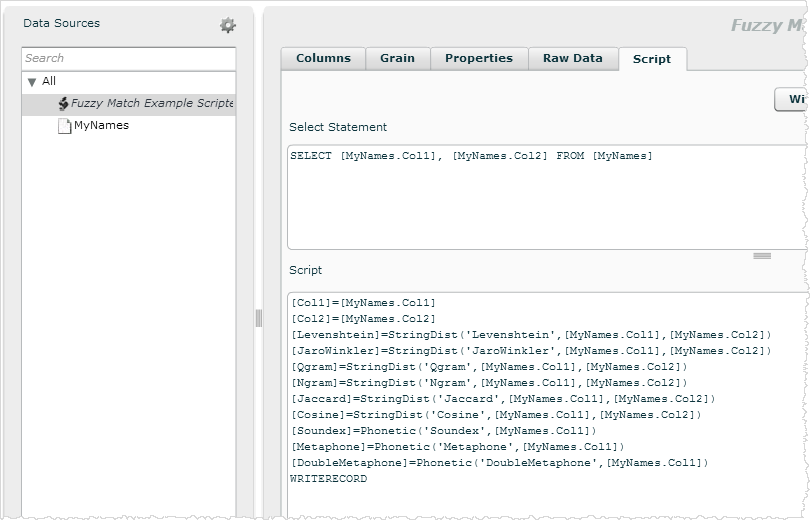
- Add the query and script. For example, the SELECT statement gets the data from the uploaded source:
SELECT [MyNames.Col1], [MyNames.Col2] FROM [MyNames]
The script runs the functions against the data:
[Col1]=[MyNames.Col1]
[Col2]=[MyNames.Col2]
[Levenshtein]=StringDist('Levenshtein',[MyNames.Col1],[MyNames.Col2])
[JaroWinkler]=StringDist('JaroWinkler',[MyNames.Col1],[MyNames.Col2])
[Qgram]=StringDist('Qgram',[MyNames.Col1],[MyNames.Col2])
[Ngram]=StringDist('Ngram',[MyNames.Col1],[MyNames.Col2])
[Jaccard]=StringDist('Jaccard',[MyNames.Col1],[MyNames.Col2])
[Cosine]=StringDist('Cosine',[MyNames.Col1],[MyNames.Col2])
[Soundex]=Phonetic('Soundex',[MyNames.Col1])
[Metaphone]=Phonetic('Metaphone',[MyNames.Col1])
[DoubleMetaphone]=Phonetic('DoubleMetaphone',[MyNames.Col1])
WRITERECORD - Click Validate. Troubleshoot if needed, then click Save.
- Click Execute to see the results in the Raw Data tab.
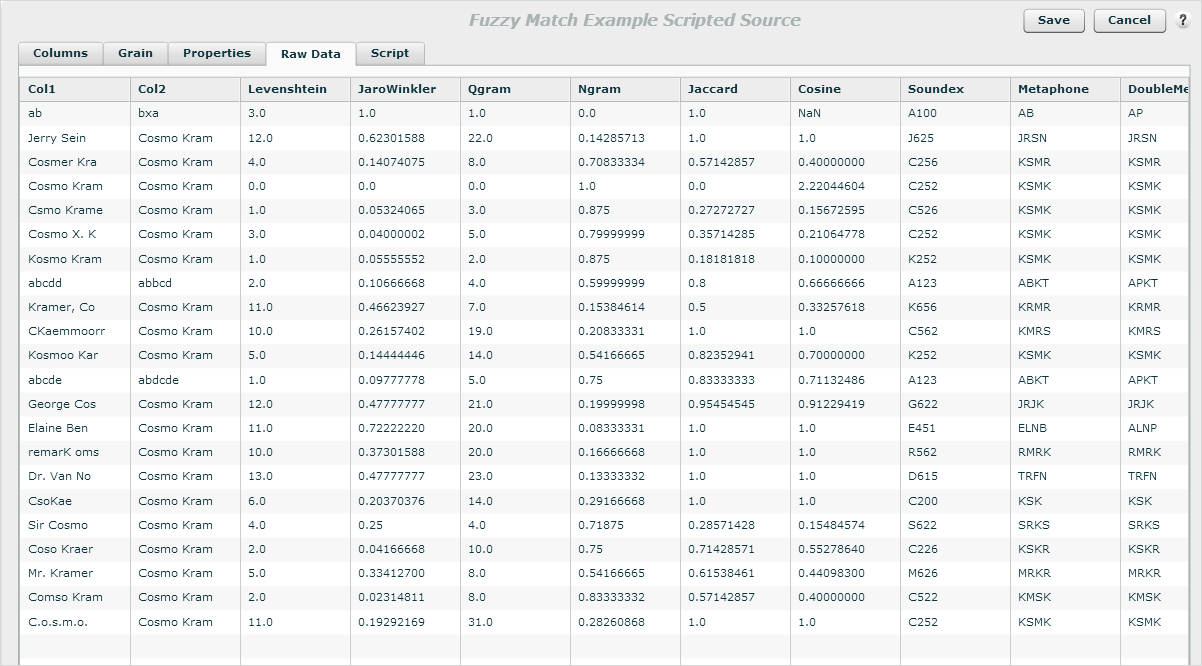
- Use these functions in your data cleansing ETL, based on the data and the matching algorithm you need.